

Cord Wischhöfer, CEO of DIN Software shares perspectives from a Standards Development Organization (SDO)
On Jan 27th, 2022, CCC brought together a panel of industry experts who presented their perspectives on the challenges faced by standards developers and standards users as they move into a dynamic future. This event was supported by the U.S. Department of Commerce’s International Trade Administration’s Market Development Cooperator Program It was well-attended by representatives from US-based, Canadian, and European standards development organizations as well as from knowledge management leaders representing top pharmaceutical companies, global engineering consultancies, and multinational energy firms. All participants had the opportunity, during concurrent breakout sessions, to weigh in from their experiences from all sides of the world of standards.
After being introduced by CCC’s own Andrew Robinson, our moderator Jonathan Clark (of Jonathan Clark & Partners BV), facilitated the discussion among:
- Tatiana Khayrullina, Consulting Partner, Standards and Technical Solutions. Outsell Inc.
- Cord Wischhöfer, CEO DIN Software GmbH
- Simon Klaris Friberg, Senior Librarian/Information Consultant, Rambøll Danmark A/S
Note to readers: We will paraphrase and encapsulate the key points made by each speaker in a series of blog posts, of which this is the second. This link takes you to a recording of the presentation itself.
DIN Software is a subsidiary company of the German Institute for Standardization, DIN e.V. They principally produce databases of standards metadata, and standards-related content. In the standards domain, DIN manages all the XML content their clients and customers use to create products.
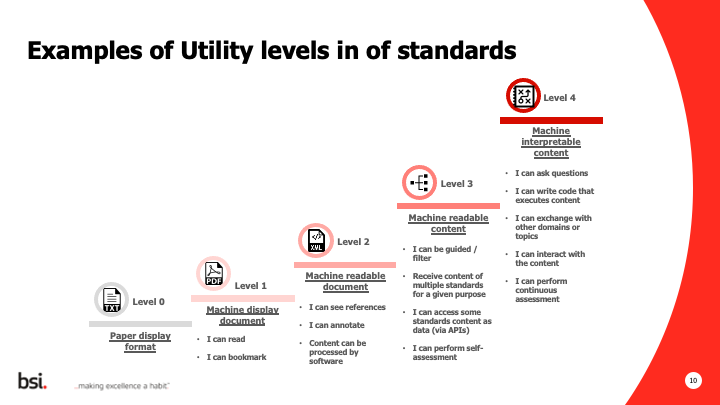
Cord Wischhöfer, our second presenter, walked us through the standards work in which DIN engages on a daily basis. I found Cord’s graphic which appears next to be eye-opening —not just for me but for others in the audience.
The graphic, reproduced here with the permission of Ivan Salcedo of the British Standards Institute (BSI), maps the levels of utility of standards and is part of the discussion surrounding smart standards at ISO, CEN and CEN-CENELEC.
The rest of this post represents my summary of Cord’s comments as he described this visual and the issues and evolution it suggests.
 This vision suggests that — in the very near future — machine-to-machine data exchange of the components of standards will become commonplace for engineering organizations. These standards may function as referral documents or perhaps as a database component in cases where customers use the data as a service. This set of future utility levels brings up all kinds of interesting questions.
This vision suggests that — in the very near future — machine-to-machine data exchange of the components of standards will become commonplace for engineering organizations. These standards may function as referral documents or perhaps as a database component in cases where customers use the data as a service. This set of future utility levels brings up all kinds of interesting questions.
In effect, the graph illustrates the observation (among many in the standards community) that until a few years ago engineers were mainly using paper versions (Level 0), and simply reading and applying this material in their work. However, over time, the use case has shifted to a machine-displayed document like a PDF (Level 1), such that it was easily viewable, the user could store it more easily and mark up the sections most relevant to their work, and so forth. But the user couldn’t really use the content, so this was basically still a relatively “dumb” document.
The levels ascend in complexity from there. Level 2 is now industry-standard such that certain standards publications already are “machine-readable” (to a degree) in that basically they are XML-structured documents based on the new NISO Standards Tag Suite (NISO STS). In other words, a cooperative venture between mainly European standards bodies and their American analogues has agreed on a common XML format for the publication of standards, but this XML format is still rather “dumb,” in a manner of speaking. It’s very much document-oriented: While it tells you that “this is a paragraph” and that “this is a normative reference,” it doesn’t really inform the user anything about the content; that is, while the verbal content is still (technically) machine-readable, it is not semantically enriched at all. One could easily identify far more sophisticated solutions, where readers could access the structured content of standards – not the whole document, but the actionable and relevant parts for the project at hand.
Level 3 postulates fully machine-readable content and that’s where we are moving to at the moment. At Level 3, the standards developer will identify certain elements and other standards relevant for user applications in industry, for example, incorporating requirements from standards into the user’s Requirements Management System.
What this means is, basically, no more cutting and pasting. Instead, users will be able to transfer sections and subsections into their requirements management system as needed. And SDOs will offer services to customers saying we can give you all the requirements from certain standards. This, at least, is our vision for the next-stage future.
Level 4, which is still on the drawing board, will arrive when the content can be called “intelligent” or “smart” — smart as in “smart phones” and “smart cars.”
In this still-a-few-years-off environment, users with be provided APIs through which they will access the required information from the intelligent standards, as discovered by intelligent search engines (not yet available), which can then answer questions which may require retrieval from a range of 10 (or possibly 20,000!) documents. We look forward to getting the right answer for the right question, just in time, for the user in need of it. That visionary state will, no doubt, be very difficult to achieve. We are working on it though, because that’s what we hear is needed from our customers.
Along with our customers, we are looking ahead to 2030 and asking: What does the world of standards look like at that point? We anticipate sentence- or provision-centric tagging in the standards content, in effect a much more granular tagging of content in standards, and we’re developing an information model that will get us there. The vision is to service applications and industry with meaningful information, with less time wasted by engineers searching for things and more time doing engineering. Eventually, we will see standards move away from the document-based standard that has existed for over a hundred years to a data-centric version, where most of the content is in formats like XML or other textual representation, and is available either via libraries or databases queried automatically or semi-automatically.
Cord concluded by expressing his hope his overview provided listeners and readers with basic and accurate idea of how, within the ISO world and among the associated national standards developers community, they are working every day to develop a new level of utility and granularity for a better user experience.
This series will conclude with the perspective of Simon Klaris Friberg (Senior Librarian/Information Consultant, Rambøll Danmark A/S).