

It might seem obvious, but not all citations are created equal.
You can cite a paper as background, you can cite a paper because you followed the same protocol, or you can cite a paper because you disagree with it. Obviously, there are many reasons to cite a paper (CiTO lists dozens here). So why do we treat citations as if they are all the same? Why does the Impact Factor of journals not consider the types of citations? Why do researchers’ h-index scores not take this fact into account? The simple answer is that historically, we have not been able to. We’re changing that at scite.
A Next Generation of Citations
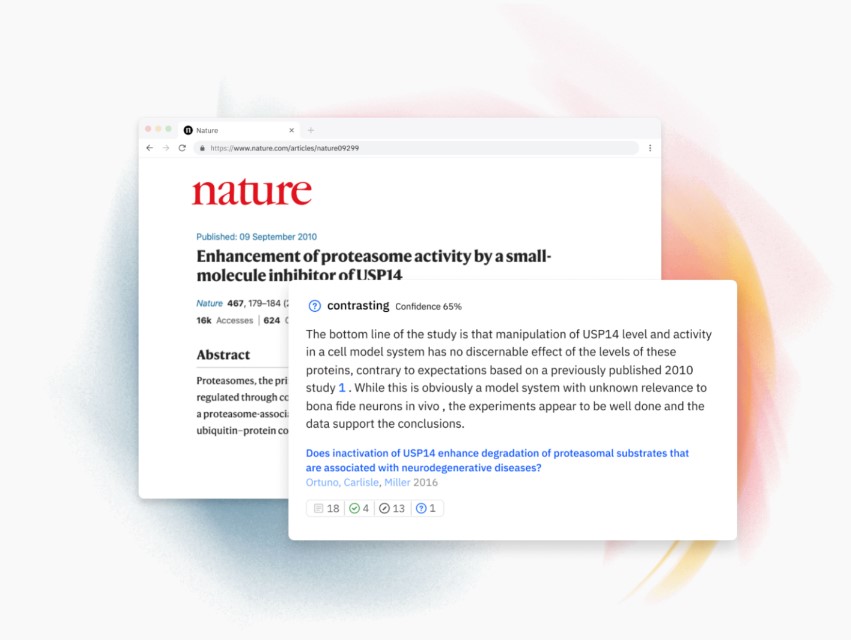
scite is working to introduce the next generation of citations, called Smart Citations. Smart Citations allow users to see how a research paper has been cited by providing the context of the citation, the location where the citation appears, and a classification describing whether it provides supporting or contrasting evidence for the cited claim. In short, the conversation changes from “how many times has this article or researcher, or topic been cited” to how has it been cited.
 The idea, while spearheaded by scite, has been discussed and attempted for decades. Eugene Garfield, the creator of the world’s first science citation index discussed adding “citation markers” to traditional citation indices in 1964. He suggested an intelligent machine could add specific markers like “critiques” or “data spurious” to citations and even presciently wrote that this could be done by an intelligent machine. His thinking was undoubtedly influenced by the fact that law does not treat citations all the same. In fact, lawyers have utilized a system called Shepardizing to make sure they cite good law for over a hundred years. Shepardizing allows lawyers and researchers to see if a case has been overturned, reaffirmed, or questioned.
The idea, while spearheaded by scite, has been discussed and attempted for decades. Eugene Garfield, the creator of the world’s first science citation index discussed adding “citation markers” to traditional citation indices in 1964. He suggested an intelligent machine could add specific markers like “critiques” or “data spurious” to citations and even presciently wrote that this could be done by an intelligent machine. His thinking was undoubtedly influenced by the fact that law does not treat citations all the same. In fact, lawyers have utilized a system called Shepardizing to make sure they cite good law for over a hundred years. Shepardizing allows lawyers and researchers to see if a case has been overturned, reaffirmed, or questioned.
Creating Smart Citations
To create Smart Citations scite requires access to the full text of research articles. Utilizing 11 machine learning models with 20 to 30 features, each scite matches the in-text citations to their corresponding reference in the reference section, then takes the reference string and matches it against metadata from CrossRef and DataCite, two centralized metadata providers. Additionally, it extracts the sentence where the citation call out is made as well as the sentence before and after this sentence. With this, a deep learning model trained off more than 40,000 manually annotated citation statements classifies if the statement provides supporting or contrasting evidence to the cited claim. For more detail on this process, you can see the peer-reviewed manuscript describing scite here.
 Thus, the challenge of gaining access to articles and then texting mining them has largely made it hard to classify citations at scale. Advances in machine learning, increases in open access, and publishers willing to partner have helped overcome these obstacles. Accordingly, scite has analyzed and extracted 1,061,873,987 citation statements from 30,099,439 full-text articles, providing Smart Citation data for 50,232,763 different papers. This information is now starting to appear on the articles themselves with journals such as PNAS now displaying Smart Citations, tools like RightFind Navigate displaying Smart Citations, and many others.
Thus, the challenge of gaining access to articles and then texting mining them has largely made it hard to classify citations at scale. Advances in machine learning, increases in open access, and publishers willing to partner have helped overcome these obstacles. Accordingly, scite has analyzed and extracted 1,061,873,987 citation statements from 30,099,439 full-text articles, providing Smart Citation data for 50,232,763 different papers. This information is now starting to appear on the articles themselves with journals such as PNAS now displaying Smart Citations, tools like RightFind Navigate displaying Smart Citations, and many others.
The introduction of this new type of citation introduces new possible workflows. Whereas it is impractical to check what each citation says about an article with traditional citations, it is now easy with scite and Smart Citations. This shift in technology has opened a shift in the usage of citations from a superficial metric that we glance at to a rich source of information.
The next time you look at a paper or topic, don’t just glance at the metrics section. Instead, think about how you can further engage with the literature and see the conversation happening amongst papers. The tools to do this are available.
Learn more about how Scite and CCC partner here.