

In part one of this series, we identified five common use cases emerging around data and content to support R&D. In this second post, we turn to the obstacles that organizations encounter when trying to meet those needs, and the capabilities required to overcome them.
Signals from across the Life Sciences industry suggest that the challenge is no longer a lack of ambition around AI in R&D, but the difficulty of sourcing data that is fit for purpose. Some useful insight into this came recently from an informal live poll conducted at a Pistoia Alliance event in Boston, which focused on data access and sourcing.
One of the clearest messages was that teams struggle to obtain content in what respondents described as “AI-ready formats.”
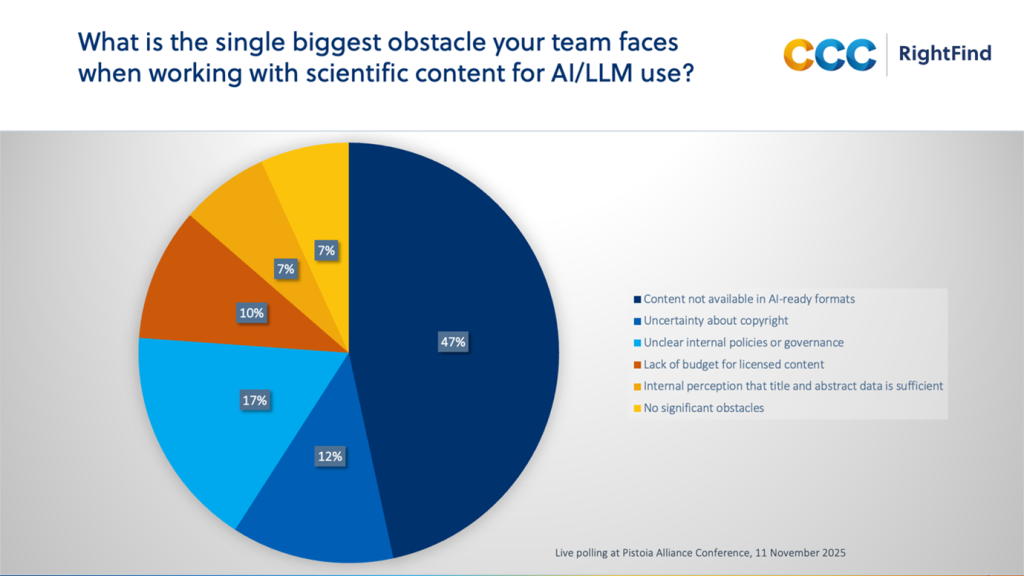
While the poll did not define precisely what “AI-ready” means, the implication is clear. Content needs to be structured, normalised, and accessible in ways that allow it to be consumed by different AI models and tools. PDFs designed for human reading are rarely sufficient on their own; machine consumption places very different demands on format and consistency.
A second, closely related concern emerged around governance and copyright. Nearly a third of respondents cited uncertainty in this area, highlighting how compliance is another key factor that feeds into the “AI-ready” label. Content may be technically usable, but if its rights status is unclear or its intended use falls outside existing licenses, it simply cannot be deployed. Organizations don’t want to advance an AI initiative only to discover that it carries unacceptable legal or reputational risk.
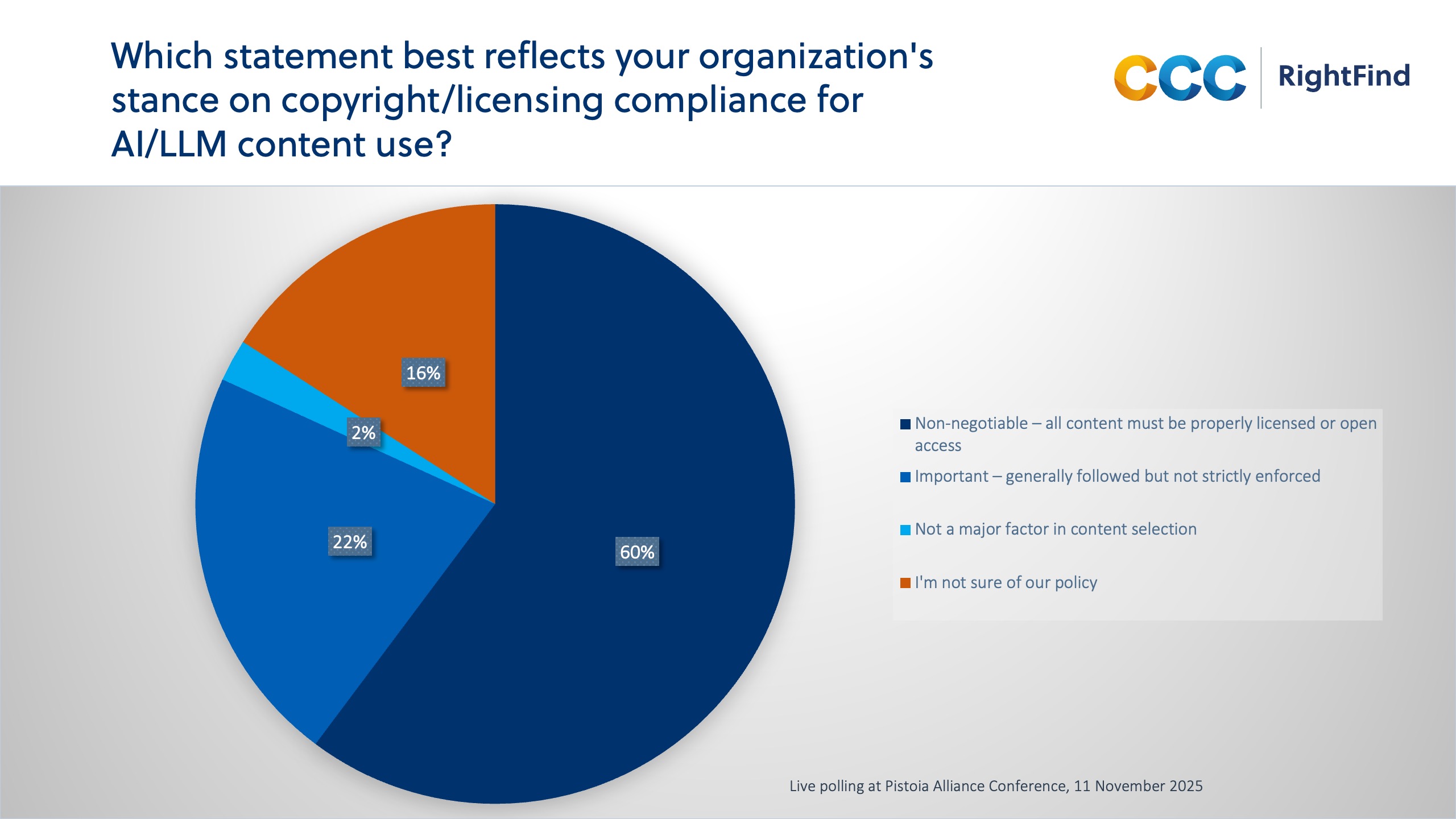
This emphasis on compliance was reinforced elsewhere in the poll. When asked about organizational approaches to licensing, 82% of respondents indicated that they take it seriously, with 60% describing it as non-negotiable. The message is consistent: AI use cases must be built on solid governance foundations.
Taken together, these findings point to a clear conclusion. It is already difficult to find content that is genuinely AI-ready, and even when such content exists, it must also be licensed appropriately for AI-driven uses. Looking at the types of content currently being used with AI tools shows how this tension is playing out in practice.
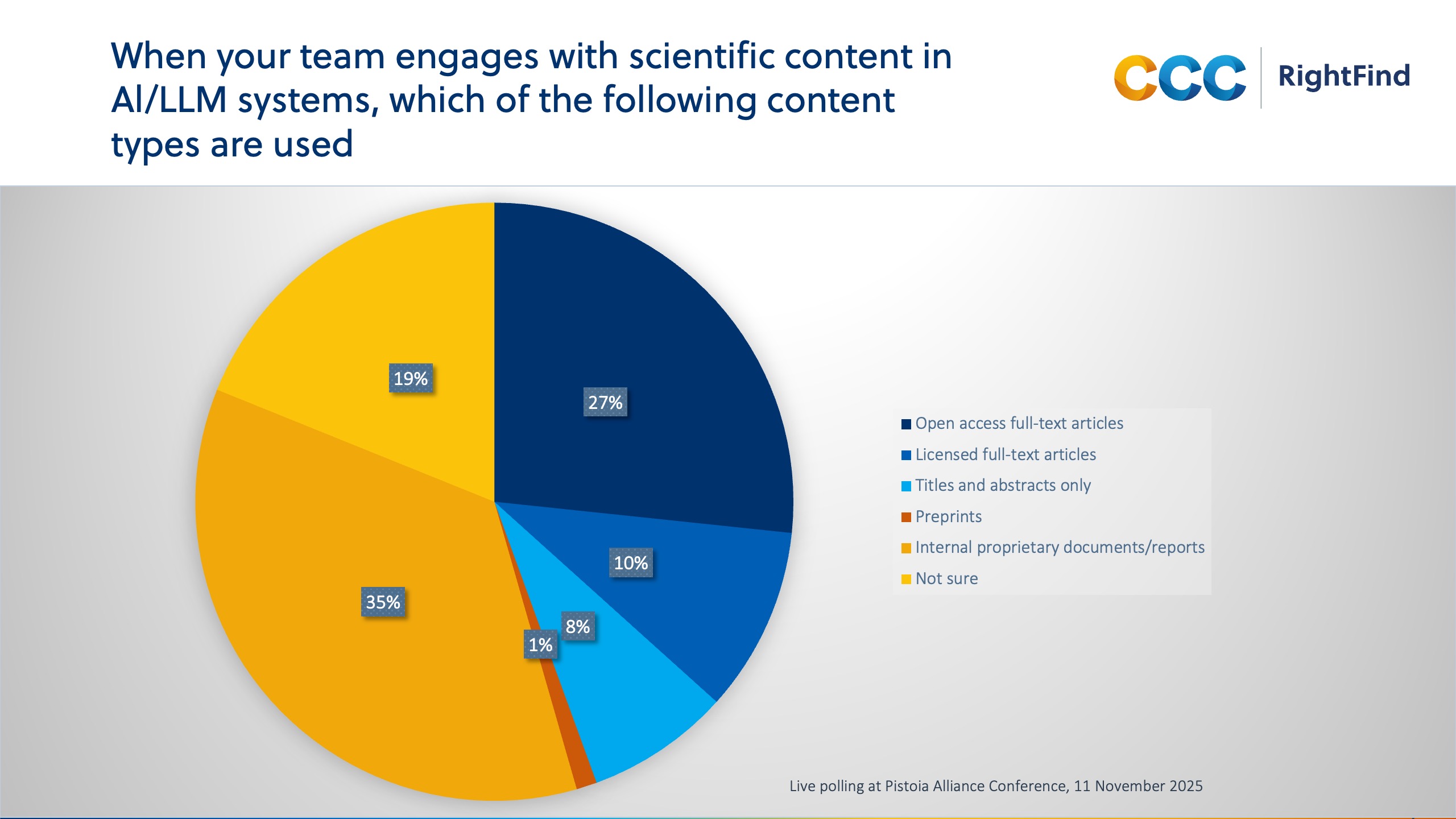
The poll suggests that licensed content is significantly underutilised in AI use cases, with most activity focused instead on open access materials or internal proprietary materials.
It’s a continuing issue: licensed, peer‑reviewed content is widely regarded as authoritative and trustworthy, yet it’s often underused in AI workflows. This isn’t due to lack of value, but instead due to lack of understanding of the need for rights compliance, potential complexity of rights management, technical access, and integration processes. As AI rights licensing options mature—through collective management organizations and direct agreements with publishers—copyright can become even more of a catalyst that fuels trustworthy, accountable AI.
One final observation from the poll is also worth highlighting. Respondents expressed concern about the lack of standards or benchmarks for verifying AI outputs. There is unlikely to be a single, definitive solution to this problem. However, starting with high-quality, trusted source material is one factor that organisations can control. Properly licensed, peer-reviewed content has an important role to play here, not only as training or input data, but as a reference point for validating outcomes. The full poll results are available on CCC’s RightFind LinkedIn page.
What does this mean in practice?
Taken together with the use cases outlined in part one, these challenges point to a simple but pressing question: where do organizations go next?
It is increasingly clear that R&D teams need a way to access large volumes of machine-consumable content that:
- respects copyright and enables effective rights management
- supports collaboration across functions and teams
- is easy to use, rather than adding friction
- enables innovation in a rapidly evolving AI landscape
All in service of a larger goal: enabling new discoveries through easy access to trusted science.
These principles are increasingly shaping how organisations design their data strategies. At CCC, they underpin much of our work with customers.
One way to address this is through a data portal or service that provides a curated, controlled route to AI-ready content. If we take that idea seriously, there are several key considerations that such a solution would need to address.
A robust approach would:
- Provide visibility into the organisation’s data inventory, with the ability to filter by need or business function
- Bring together data sources from multiple providers in a single place
- Make licensed content, along with its permitted uses, easy to discover and consume
- Automate rights-checking across content, regardless of source, to ensure intended uses are allowed and properly governed
- Enable programmatic access so machines can locate, check, and consume data without manual intervention
- Normalise data formats or access methods to make content usable across different tools, particularly AI systems, to make it “AI-ready”
- Support both human and machine interaction, allowing flexibility across a wide range of use cases
The potential benefits of this kind of approach are significant.
Workflows, from identifying a need for data to actually obtaining it, could be dramatically shortened. Concerns could be separated more cleanly: those focused on machine consumption would have a dedicated pathway, while human-readable access would continue to serve its own purposes. Stronger compliance would be easier to maintain through improved tracking, reporting, and usage insight.
Perhaps most importantly, organizations would gain a clearer view of the content they already have, the rights attached to it, and the gaps that still need to be filled. Knowing what you can use, and therefore what you are missing, makes it far easier to invest intelligently.
These are the capabilities that organizations should be striving for, regardless of how they are ultimately delivered. The precise form such a solution takes is open for debate.
How organizations respond to these challenges will shape the future of AI in R&D.
What is clear from conversations with CCC’s customers and partners is that there is a real need to support AI use cases with content that is reliable, trustworthy, and easy to work with. Data portals or services that focus on finding, accessing, and delivering AI-ready content – both from inside and outside the organization – have the potential to act as powerful enablers for R&D. Copyright and rights governance must be built in from the outset, and adoption will depend on two additional factors above all else: simplicity and the ability to adapt as requirements evolve.
So what’s your story? Do the use cases from part one resonate with your experience? How are you addressing the challenges outlined here? I’d welcome the conversation, and the opportunity to work together to make this new frontier one where AI-ready content is easy to find, easy to trust, and easy to use.