
Finding the missing pieces of the puzzle
I think one of the most-used phrases of 2020 is “these are unprecedented times.”
I did hear another phrase recently that I liked: it is a “dark privilege” to be living through this global pandemic. No doubt, we live in an interesting time! In decades to come, people will talk about 2020 and the impact of coronavirus on so many global factors – economy, climate, travel, and of course population and individual health. As well as the dark clouds, there is of course light – and much light comes from the collaborative efforts of institutions, healthcare organizations and governments to find the best responses to this challenge, particularly in the areas of drug repurposing and vaccine development.
And this, to me, is where natural language processing-based text mining comes in. Whenever scientists, researchers and clinicians are faced with a challenge, one critical asset is identifying as much information about the problem as possible. Whatever information there is, locally and globally, that can be found, gathered and understood, will enable the right decisions to be taken. Relevant information on the biology of SARS-CoV2, from COVID-19 as a disease, patient demographics and co-morbidities, global or regional spread, and possible drugs that might treat the symptoms and impacts of this disease is all just the tip of a data iceberg. Much of this data exists in unstructured text: scientific papers, preprints, clinical trial records, adverse event reports, electronic healthcare records, even news feeds and social media can all provide information on epidemiological factors, for example.
This is where AI technologies such as NLP can play a part. NLP-based text mining uses a toolbox of methodologies including linguistic processing, machine learning, regular expression, ontologies and more to transform the free (unstructured) text in documents and databases into normalized, structured data suitable for visualization or analysis. NLP enables researchers to access information from sources such as scientific literature, clinical trial records, preprints, internal sources, social media, and news.
Capturing key information from a variety of sources and synthesizing into one platform gives users a deeper understanding of everything that’s going on. This approach can speed answers to key questions to confront the COVID-19 pandemic, such as: What are the best potential drugs for repurposing efforts? How do I find recent trials, the most up-to-date research, and the key opinion leaders and researchers in this field? Who in the population is most at-risk for severe disease? What are the key co-morbidities? What additional care pathways are needed for patients post-COVID-19?
NLP use in pharma and healthcare organizations for COVID-19 understanding
One example of an innovative approach to better patient care comes from a large U.S. Health System. They were concerned about under-reporting of COVID-19 cases, so they used NLP to mine incoming emails and chat messages from their patient help line, for a suite of COVID-19 related symptoms. They then ran analytics to classify these patients according to the likelihood of having COVID-19. This was an automated process, in near real-time, which enabled clinicians to more effectively manage the patient population.
Another example comes from a pharmaceutical company who wanted to mine social media to understand COVID-19 spread and risk factors. Again, a set of queries were written to categorize patient behaviors according to various factors, e.g., mentions of medical facilities being attended. They also analyzed the social media messages to understand COVID-19 status and risk across a spread of professions and occupations.
Organizations are also using NLP to access the landscape of scientific papers relevant to the coronavirus pandemic. Researchers developing COVID-19 therapeutics use NLP to track new papers, particularly around drug or vaccine safety. Publishers have come forward to offer free access to critical literature; for example, the CORD-19 Dataset compiled by the Allen Institute for AI; Elsevier Coronavirus Dataset ; and Copyright Clearance Center COVID-19 collection. These fantastic resources can be mined to find drug efficacy or safety profiles, understand co-morbidity profiles, the natural history of the virus and disease, and who in the population is most at risk for severe disease.
What does the future hold?
The recent review in Nature emphasizes that COVID-19 is here to stay, and our future depends on many unknowns. The author ends with a quote from a senior epidemiologist: “There is so much we still don’t know about this virus. Until we have better data, we’re just going to have a lot of uncertainty.” NLP can assist in some way with enabling access to data, and hopefully therefore to resolve some of that uncertainty.
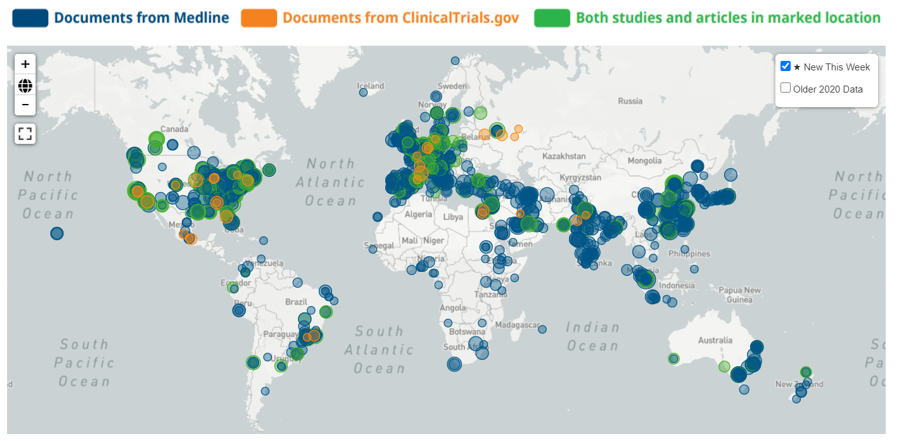
Figure 1: COVID-19 relevant data mined with NLP. Since the start of the pandemic there has a huge growth in the number of research papers generated relating to COVID-19, and while generally clinical trial enrolments have fallen, COVID-19 related clinical trials have been taking place worldwide. The map shows locations around the world where COVID-19 studies are being run and COVID-19 scientific abstracts are being written. Linguamatics NLP is used to automatically extract COVID-19 related documents from the MEDLINE® and ClinicalTrials.gov indexes in the Linguamatics Content Store. Please see https://covid19.linguamatics.com/ for more information.
As the Human Data Science company, IQVIA is ready to help reduce the impact of COVID-19 today and provide hope for the future.